Welcome to the Compack3D user guide. Compack3D is an open-source project developed at Stanford University and supported by the National Science Foundation. Compack3D is relased under the Apache-2.0 License
. This package provides optimized implementations of essential algorithms for rapid development of numerical solvers for partial differential equations.
Why do I need it?
Compack3D is a light-weight package, originally designed for computational scientists who use compact finite difference methods (generalized Padé schemes) to accelerate their solvers. It solves the tridiagonal and penta-diagonal systems arising from compact numerical schemes on 3D computational mesh. Compack3D provides efficient solutions for hiearchical parallelization on distributed memory and shared memory and enables affordable large-scale simulations using compact finite difference methods. Compack3D provides both C++ and Fortran APIs, which makes it easy to interface with your own application, even a legacy code.
How to cite our work
If your project benefits from Compack3D, we would appreciate it if you add the following works to your reference list
@article{song2022scalable,
title={Scalable parallel linear solver for compact banded systems on heterogeneous architectures},
author={Song, Hang and Matsuno, Kristen V and West, Jacob R and Subramaniam, Akshay and Ghate, Aditya S and Lele, Sanjiva K},
journal={Journal of Computational Physics},
volume={468},
pages={111443},
year={2022},
publisher={Elsevier}}
This project is led by Prof. Sanjiva K. Lele and the core development team consists ofProf. Sanjiva K. Lele
Project P.I.
Stanford University
lelestanford.edu
Dr. Hang Song
Core developer
Stanford University
songhangstanford.edu
Andy Wu
Developer
Stanford University
awu1018stanford.edu
Anjini Chandra
Developer
Stanford University
achandr3stanford.edu
1 - Installation
Prerequisites
Compack3D is implemented in C++ using the C++20 standard. The parallelization follows the “MPI+X” paradiam. The following packages are required:
C++ compiler
“X” compiler for CUDA or HIP
CMake (minimum version 3.23)
Message Passing Interface (MPI)
The HIP feature is still under development.
The package will be updated soon.
Download Compack3D
The source code of Compack3D
is hosted on GitHub.
We highly recommend that users obtain the source code using Git.
To do this, navigate to the target directory where the Compack3D will be placed and paste the following command:
Compack3D provides CMake support to build the project.
CMake v3.23 or above is required.
To build Compack3D, first navigate into the Compack3D root directory <path/to>/Compack3D/.
Then, create a build directory and navigate into it.
mkdir build &&cd build
Make sure to load all necessary modules, e.g., compilers, CMake, and MPI.
For more detailed usage of CMake, please refer to the official CMake documentation
Available optional variables are listed in the following table.
Variable Name
Type
Explanation
CMAKE_BUILD_TYPE
STRING
Valid values are Debug, Release, Profiling, or Help. The Debug mode enables safe launch check and does not enable compiler optimization. Default value is Release.
CMAKE_INSTALL_PREFIX
STRING
A valid path with rwx permission. Install root directory. Default is ./
COMPACK3D_ENABLE_DEVICE_{TYPE}
BOOL
Default is OFF. Valid of {TYPE} is CUDA or HIP. Different devices cannot be enabled in one build.
COMPACK3D_DEVICE_ARCH
STRING
Specification of the device architecture. Needs to be consistent with the specified device type. Valid values are Default, V100.
COMPACK3D_ENABLE_DEVICE_AWARE_COMM
BOOL
If enabled, use GPU-to-GPU communication.
COMPACK3D_BUILD_UNIT_TESTS
BOOL
Compile unit tests associated with the specified device.
COMPACK3D_BUILD_BENCHMARK_TESTS
BOOL
Compile benchmark tests associated with the specified device.
COMPACK3D_MPI_EXEC_PREFIX
STRING
MPI launcher and flags, required for unit tests. This value can be alternatively set by environmental variable COMPACK3D_MPI_EXEC_PREFIX. Default value is mpiexec -n 1, and a warning will be raised.
Linking to your own project
We working on it…
2 - Usage
Compack3D is mostly implemented in C++, and it also provides Fortran interfaces using ISO_C_BINDING.
In order to improve the performance, the tridiagonal and penta-diagonal solvers in Compack3D prefactorize the linear systems.
Buffer for distributed communication is also required.
Depending on the system size, grid decomposition strategy, device that supports the solution process, and communication pattern,
the allocation of the buffer variables is application-specific.
Additionally, the buffer may be able to be reused for solving different linear systems on the same computational grid.
Compack3D supports customized memory allocation and management.
It also provides built-in memory allocators and deallocators.
The tridiagonal and penta-diagonal solvers in Compack3D can be used in either pure function calls or object member function calls.
From the perspective of simplifying the memory management, object member function calls are recommended.
Namespace (::cmpk)
For C++ programming interface, Compack3D is protected by the namesapce ::cmpk.
In the following context, the base namespace, ::cmpk, is assumed.
Memory space
The concept of memory space is used in Compack3D to indicate the locality of the data and instruct the kernel launching.
Compack3D defines two types of memory space:
MemSpace::Host host memory
MemSpace::Device device memory
The host memory (MemSpace::Host) is guaranteed to be accessible by a CPU thread.
If a GPU is specified as the device, the device memory space (MemSpace::Device) will be the GPU memory.
Otherwise, the device memory is the same as the host memory.
Using a CPU as the device indicates that a “kernel” will be launched on the CPU with shared-memory parallelism, and the execution will be mapped to OpenMP.
High-level APIs
Compack3D provides high-level application programming interfaces (APIs).
The solvers are wrapped into C++ templated classes.
The data locality and factorization coefficients are automatically managed internally throughout the lifetime of a solver object.
For efficient memory usage, memory buffers for solvers on the same computational mesh and mesh partition strategy can be shared.
In order to use the high-level APIs, the header file Compack3D_api.h is required.
Some utility functions for memory management are provided.
These utility functions enable single implementation for various runtime architectures.
Memory management
The memory allocation and deallocation are managed by memAllocArray and memFreeArray, respectively.
The signatures are provided below:
where MemSpacetype can be either MemSpace::Host or MemSpace:Device;
and memFreeArray only requires the value of the pointer pointing to the allocated memory address.
memAllocArray takes the address of a pointer as DataType** and a count of memory in the group of sizeof(DataType) as unsigned int.
memAllocArray and memFreeArray only take raw pointers, which do not assume any higher-level data structures.
For a multi-dimensional array, the count is the total number of entries including the padded entries.
To reduce the chance of causing memory leak, memAllocArray requires that *ptr_addr must be a null pointer, nullptr.
Otherwise, a runtime error will be thrown.
Deep copy
A deep copy of an array can be conducted using the built-in utility function deepCopy.
deepCopy automatically maps to a reliable method for safe deep copy of data from host to host, from device to device, or between host and device.
The signature of deepCopy is
The type arguments DstMemSpaceType and SrcMemSpaceType represent the destination and source memory space types respectively.
The valid types are MemSpace::Host and MemSpace::Device.
DataType is an atomic data type of the arrays.
The function arguments dst and src are the raw pointers of the destination and source buffer respectively. count is the count of DataType entries.
Solver APIs
The tridiagonal and penta-diagonal solvers operating on a 3D partitioned computational mesh are:
DistTriSolDimI – solving a tridiagonal system along the dimension i.
DistTriSolDimJ – solving a tridiagonal system along the dimension j.
DistTriSolDimK – solving a tridiagonal system along the dimension k.
DistPentaSolDimI – solving a penta-diagonal system along the dimension i.
DistPentaSolDimJ – solving a penta-diagonal system along the dimension j.
DistPentaSolDimK – solving a penta-diagonal system along the dimension k.
The convention of a 3D dimensional array index is (i, j, k), which holds for both C- and Fortran-order memory layouts.
For the C-order layout, the index k maps to contiguous memory access,
while for the Fortran-order layout, the index i maps to contiguous memory access.
For simplicity, denote DimX be an arbitrary dimension of {DimI, DimJ, DimK}.
Construction
All the listed solvers do not support default construction.
The signatures of the tridiagonal and penta-diagonal solves are:
The construction signature contains the description of the decomposed computational mesh in the local distributed memory partition.
The template argument RealType represents the atomic floating-point (FP) type.
Currently supported types are FP64 and FP32.
The communication between distributed memory partitions includes mixed-precision operations.
The template argument RealTypeComm indicates the reduced-precision FP type.
If RealTypeComm is same as RealType, then no mixed-precision operation will be performed.
RealTypeComm is an optional argument, which is default to RealType.
The precision of RealTypeComm must be less or equal to that of RealType.
Otherwise, a compile error will be raised.
The mixed-precision operation can, though is not guaranteed to, result in the higher-precision accuracy.
The accuracy depends on the runtime computational mesh size and the mesh partitioning strategy as well as the linear system itself.
Current development includes a runtime check feature to estimate the magnitude of the final round-off error.
The template argument MemSpaceType indicates the data locality.
Valid types are MemSpace::Host and MemSpace::Device.
Here, the data refers to the input and output during the solution process.
The MemSpaceType must be consistent with the locality of the shared buffer.
The allocation of all internal buffers is guaranteed to be consistent with the specified MemSpaceType.
The arguments num_grid_i, num_grid_j, and num_grid_k, are number of grid points in the current distributed-memory partition.
These numbers only count for valid grid points. Do not count any padded entries.
The arguments arr_stride_i and arr_stride_j are the memory strides in terms of counts of entries on the linear allocated memory.
These arguments provide instructions for accessing the 3D array from (i, j, k) to (i+1, j, k) and from (i, j, k) to (i, j+1, k), respectively.
The argument mpi_comm is an MPI sub-communicator that only contains the partitions involved in an individual solution process.
This means that the MPI sub-communicator should only contain the pencil of partitions along the solve dimension.
See the figure of schematics
for more details.
The ranks assigned by mpi_comm must be continuous integers starting from 0.
The solution process uses the ranks to determine the data locality in different distributed memory partitions.
Low-level APIs (use with caution)
All low-level APIs in Compack3D are included in the high-level APIs.
The high-level APIs provide extensive flexibility for using the solvers in a variety of scenarios.
Although the low-level APIs offer much more flexibility, we still highly recommend using the high-level APIs if they are sufficient.
Again, we highly recommend to using the low-level APIs only when absolutely necessary.
If you have carefully read the previous paragraph and still decide to use the low-level APIs, the instructions are listed as follows.
The possibly-needed header files are listed below:
Compack3D_util.h constains all the utility functions
Compack3D_tri.h contains all the low-level functions for the tridiagonal solvers
Compack3D_penta.h contains all the low-level functions for the penta-diagonal solvers
The low-level functions for the tridiagonal and penta-diagonal solvers are protected within the namespace ::cmpk::tri and ::cmpk::penta respectively.
This section is still under construction and will be updated soon.
3 - Algorithm Description
Overview
The algorithm used in the compact banded linear system solvers assumes that the computational grid is decomposed into distributed memory partitions.
During the solution process, a pencil of distributed memory partitions is involved.
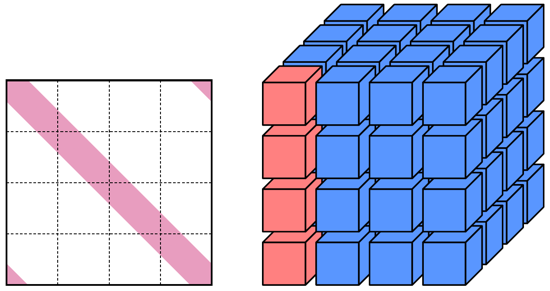
A figure below shows an example of solving the linear system in the vertical dimension, and a pencil of four partitions involved in the linear system is higlighted in red.
For numerical schemes that are applied to a periodic domain, the linear systems also contain non-zero cyclic entires.
The linear solvers provided in Compack3D support this mathematical structure.
Compact banded linear system formulated across 3D partitioned grid. A pencil of partitions involved in the solution process is highlighted in red.
The algorithm considers hiearchical parallellsms with heterogeneous memory access, and has much lower communication footprint across distributed memory partitions.
These designs make the algorithm suitable for computations using multiple GPUs or multi-core CPUs on the modern high-performance computing architectures.
Basic elimination patterns
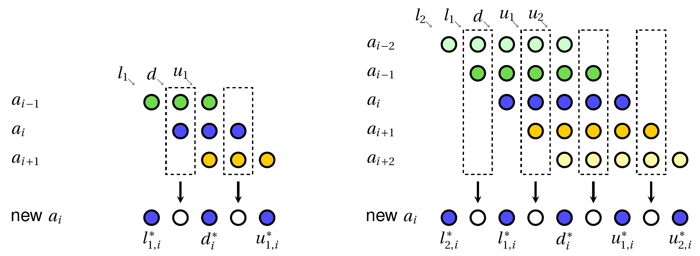
The basic elimination pattern used in the compack banded linear solvers in Compack3D follows the cyclic reduction (CR) algorithm (Buzbee, Golub, and Nielson, SIAM J., 1970) and its fully parallel variant known as the parapllel cyclic reduction (PCR) algorithm.
In each elimination step, the original off-diagonal entries in a row are eliminated by the neigboring rows.
For a tridiagonal system, two neighboring rows participate in each elimination process, and for a penta-diagonal system, each elimination step involves four neighboring rows.
In general, as the result after each elimination step, the row has the same number of off-diagonal entries but staggered with zero entries.
The staggered zero entries indicate that the current row has even or odd decoupling from the original system,
i.e., if the current row is an even-number row, it only couples with other even-number rows in the system,
and if the current row is an odd-number row, it only couples with other odd-number rows in the system.
The schematics of the basic elimination processes for a tridiagonal and penta-diagonal systems are shown in the following figure.
Basic elmination process for tridiagonal systems (left) and penta-diagonal system (right) generalized from the cyclic reduction algorithm (Buzbee, Golub, and Nielson, SIAM J., 1970).
Distributed parallelism
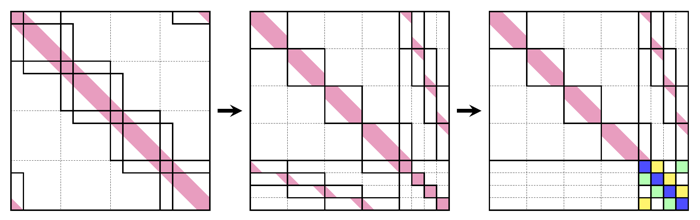
From a view of the entire pencil of distributed memory partitions involved in the linear system, the solution process is equivalent to conducting parallel block Gaussian elimination, as shown in the figure below.
As the outcome of the block Gaussian elimination, a block upper triangular system is obtained.
The last diagonal block is an independent small block tridiagonal formulated across distributed memory partitions, known as the reduced system.
Once the reduced system is solved, the remaining systems can be then solved in parallel within each distributed memory partition.
The reduced system is solved using the block PCR across the distributed memory partitions, and other diagonal blocks are solved using PCR with shared-memory parallelism.
Solution process viewing from distributed memory partitions analogous to parallel block Gaussian elimination:
(left) original system with further logical partitions,
(middle) logical collumn and row permutations,
and (right) resulting structure after block Gaussian elimination.
The reduced system is formulated across distributed memory partitions as the last diagonal block.
The reduced system is block tridiagonal formulated across the distributed memory partitions.
The block size is equal to the number of off-diagonal entries on each side.
The total size of the reduced system is equal to the number of the distributed-memory partitions participated in the solution process.
The non-zero cyclic entry blocks exist in the reduced system if the original system is also cyclic.
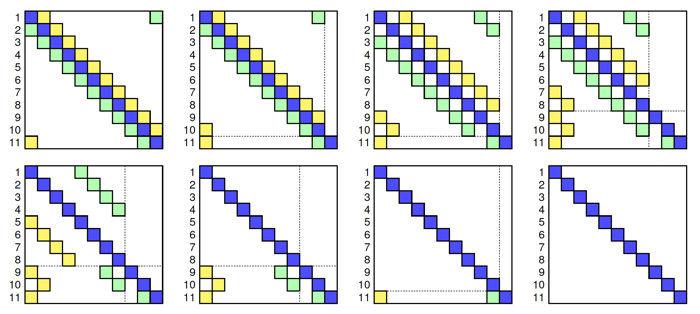
Traditional PCR approach naturally solves a cyclic system of a power-of-two size or a non-cyclic system.
If a reduced system is cyclic and whose size is not a power-of-two, Compack3D applies the method of attaching and reattaching to avoid extra communication or non-parallelizable steps in the traiditional methods.
A schematic of the solution process for an 11-by-11 cyclic reduced system is shown in the figure blow.
An example of solving a 11x11 reduced system using parallel cyclic reduction with the method of detaching and reattaching.